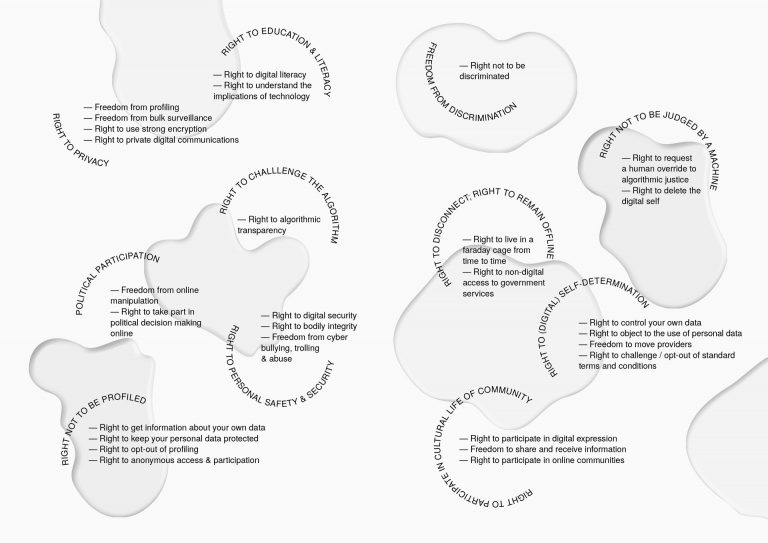
A short history of predictive mathematics
In their exchange of letters, Blaise and Pascal created the mathematical foundations needed for predictive analytics. Predictive analytics describes the practice of “extracting information from existing data sets in order to determine patterns and predict future outcomes and trends”. A number of statistical techniques are today used to conduct predictive analytics, including data mining, modelling, and machine learning, all of which are intended to analyse historical information, or rather, data gathered in the past in order to make predictions about what is unknown and what is to come. Predictive analytics can assess what is likely to happen in the future based on the input data but cannot predict what will happen in the future, even though we often we make the mistake of believing it does exactly that.
Today, we live in a world driven by prediction through data and algorithms. Every day, we let algorithms shape our decisions about the movie we might watch or which stocks to invest in. Algorithms predict which advertisements we’re most likely to react to and what choices self-driving cars should make. Our data is gathered with or without consent and harvested by data scientists who use it to “guess the future”. This is not a negative development per se. Many social use cases are being developed, such as the predictive models developed for the John Jay College of Criminal Justice in New York City to help identify which students are at risk of dropping out of college and support them through to graduation. In our increasingly complex and information-laden world, algorithms can be important tools to help us understand what’s important in our environment.
Why is relying on big data prediction a bad idea?
The data-driven realities and futures we are creating are based on the data of the past. To break free of the backward-looking, deterministic structures we are programming today, we need to complement these data. In her TedxCambridge talk, ethnographer and data scientist Tricia Wang explains how having more data does not help us “make better decisions,” when we leave out important, contextualizing perspectives. Instead, she argues for the humanization of data – what she calls “thick data” – big data that has been enriched with non-quantifiable, qualitative data gathered from an ethnographic perspective that “delivers depth of meaning”. Wang draws this conclusion based on her own experience in China in 2009, when she predicted the triumph of the smartphone over the feature phone. At the time, her client Nokia was unwilling to listen to the stories she collected behind the data and instead clung to the belief that people would not be willing to invest so much of their income in such a fragile device.
Polls and other forms of prediction, such as forecasting, fail when data is read without paying attention to the more nuanced shifts in political alliance and voter mobilization, for example President Trump’s election and the UK vote for Brexit. In order to use data effectively, we have to learn to see what the data does not show us. As Wang warns, “There is no greater risk than being blind to the unknown”.
The power of speculation and the political imagination in glimpsing the unknown
Speculation is one such tool. It is the process of “forming of a theory or conjecture without firm evidence” or “the activity of guessing possible answers to a question without having enough information to be certain”. In today’s data-driven society, speculation can be liberating. As Anthony Dunne and Fiona Raby argue in their book ‘Speculative Everything’:
We believe that by speculating more, at all levels of society, and exploring alternative scenarios, reality will become more malleable and although the future cannot be predicted, we can help set in place… factors that will increase the probability of more desirable futures happening…equally, factors that may lead to undesirable futures can be spotted early on and addressed or at least limited.
In 1952, around three hundred years after Blaise and Pascal’s correspondence enabled people to calculate probability, Christopher Strachey created what has been called the first piece of digital literary art, a combinatory love letter algorithm for the Manchester Mark 1 computer. Today, generative AI is top of the agenda for digital policy makers, activists and theorists. As a society, we are dealing with questions such as what tasks AI should be allowed perform, how to tell the difference between works created by AI and by humans, and how much decision-making power AI should have over our lives. At the same time as we teach our machines to create, let us retain our own creativity and agency to explore what can be achieved through them, rather than relying on them to predict our futures according to our pasts.